광학 텍스트 인식 또는OCR은 이미지나 인쇄된 텍스트를 기계가 읽을 수 있게 변환시키는 소프트웨어 과정입니다. OCR은 스캐너를 이용해 종이문서를 전자 문서로 만들 때 많이 사용되지만 이미 만들어진 전자 문서에도 사용됩니다. (예: PDF)
OCR 기능을 지원하기 위해서는 애드온에 언어별 팩이 설치되어 있어야합니다. 도움말 > 업데이트 확인에서 언어팩을 다운받아 추가로 설치합니다.
이때 설치하는 팩은 OCR_Lang_Korean.fzip 과 OCR_Public.fzip 파일입니다. 영어 팩은 기본적으로 설치되어 있습니다.
텍스트 인식 #
자유PDF는 PDF 파일의 스캔 여부 또는 이미지 기반을 감지하고 스캔 또는 이미지 기반 PDF를 열 때 OCR을 시작하도록 해당 제안을 할 수 있습니다.
파일에서 이미지 기반 또는 스캔된 텍스트를 인식하려면 다음 단계를 수행하십시오.
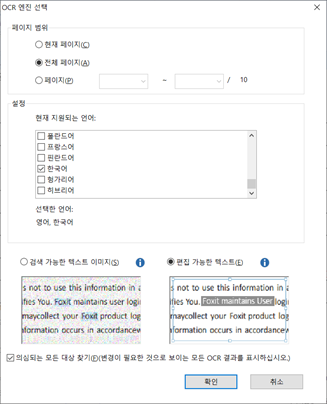
1. 변환> OCR> 현재 파일을 클릭하고 OCR 엔진 선택 대화 상자에서 필요한 범위를 지정하십시오.
2. 문서에 사용된 언어를 선택하십시오. 여러 언어를 선택할 수도 있습니다.
3. 출력 유형에서 검색 가능한 텍스트 이미지를 선택하여 이미지 텍스트를 검색할 수 있게 하십시오 (또는 편집 가능한 텍스트를 선택하여 이미지 텍스트를 자유PDF로 편집 할 수 있게 하십시오). 텍스트를 인식하려면 확인을 클릭하십시오.
참고 : 확인을 클릭한 후 OCR 구성 요소를 다운로드하라는 메시지가 표시되면 예를 클릭하여 다운로드하여 설치하거나 제공된 링크에서 나중에 다운로드 한 후 도움말 탭에서 업데이트 설치를 클릭하여 설치하십시오.
(선택 사항) 의심되는 모든 대상 찾기 (변경해야 할 수도있는 모든 OCR 결과 표시)를 선택하면 인식이 완료된 후 바로 확인하고 수정할 수있는 OCR 의심 대화 상자가 나타납니다. OCR 용의자는 거의 인식할 수 없거나 올바르게 인식되지 않아 수동으로 수정해야 하는 텍스트를 말합니다. OCR 의심 항목을 수정하는 방법은 OCR 의심항목 찾기 및 수정을 참조하십시오.
4. 진행률을 나타내는 인식 텍스트 프로세스 표시 줄이 나타납니다.
5. 검색 기능을 사용하면 이미지의 텍스트 또는 스캔한 문서를 검색할 수 있습니다.
팁 : 자유PDF는 원 클릭 / 이미지 기반 PDF의 모든 페이지를 한 번의 클릭으로 기본 또는 이전 설정으로 인식 할 수있는 빠른 OCR 명령을 제공합니다.
여러 파일에서 텍스트를 인식하는 방법 #
1. 변환> OCR> 다중 파일을 클릭하십시오.
2. OCR 다중 파일 대화 상자에서 파일 추가를 클릭하여 파일, 폴더 또는 현재 열려있는 파일을 추가합니다. 위로 이동, 아래로 이동 및 제거를 사용하여 파일 순서를 조정하십시오.
3. 출력 옵션…을 클릭하십시오. 출력 옵션 대화 상자에서 대상 폴더를 선택하고 새 파일의 이름을 지정하는 방법과 기존 파일을 덮어 쓸 지 여부를 선택한 다음 확인을 클릭하십시오.
4. 확인을 클릭하십시오. 인식이 끝나면 인식이 완료되었음을 알리는 메시지 상자가 나타납니다.
참고 :
a. CJK OCR 엔진을 처음 사용하는 경우 시스템은 자유소프트 서버에서 엔진을 다운로드하여 설치하라는 메시지를 표시합니다.
b. 지원되지 않는 파일이 추가 된 경우 OCR 다중 파일 대화 상자에 “지원되지 않는 파일 제거”버튼이 나타납니다. 버튼을 클릭하여 지원되지 않는 파일을 제거한 다음 계속하십시오. 자유PDF는 PDF 포트폴리오를 인식하는 동안 포트폴리오의 PDF 파일만 추출하고 인식합니다.
OCR 의심되는 결과 찾기 및 수정 #
PDF 파일에서 이미지 기반 또는 스캔된 텍스트를 인식한 후 아래 단계에 따라 불확실한 텍스트 또는 문자를 선택하고 수정할 수 있습니다.
1. 변환> 의심되는 결과> 첫 번째 의심 대상을 클릭하십시오. OCR 의심 대상 찾기 대화 상자가 나타나고 모든 OCR 의심 항목이 빨간색 상자로 묶여 있습니다.

참고: 기본적으로 검사 결과는 문서 검색을 기본으로 합니다. 또한 페이지 검색을 선택해서 현재 페이지의 추정 대상을 다시 찾을 수 있습니다.
2. OCR 의심 찾기 대화 상자에 원본 문서 텍스트와 OCR 텍스트가 모두 표시됩니다. 필요한 경우 OCR 텍스트 상자에서 직접 텍스트를 편집할 수 있습니다. 원래 텍스트가 아닌 일부 컨텐츠가 잘못 식별되면 텍스트 아님을 클릭하십시오. 다음 의심을 찾으려면 다음 찾기를 클릭하고 수락 및 찾기를 클릭하여 OCR 텍스트를 수락하고 다음을 찾으십시오.
3. (선택 사항) 문서에서 잘못된 텍스트를 직접 클릭하고 OCR 의심 찾기 대화 상자의 OCR 텍스트 상자에 올바른 텍스트를 입력할 수도 있습니다.
4. 닫기를 클릭하여 OCR 의심 찾기 대화 상자를 종료하십시오.
5. (선택 사항) 변환> 의심 결과> 모두 체크 표시를 선택한 경우, OCR 용의자 대화 상자가 나타나고 모든 OCR 의심 단어가 빨간색 상자로 둘러싸인 상태에서 한 번에 여러 추정 결과를 선택하고 수정할 수 있습니다.